
 Touch in Healthcare")
PHI vs Non‑PHI: What AI Can (and Shouldn’t) Touch in Healthcare
The First Boundary AI Teams Get Wrong
Most healthcare AI initiatives don’t start with compliance. They start with a use case. A team wants to summarize clinical notes, build a triage assistant, automate intake, or analyze patient messages. The fastest way to validate the idea is to connect to a model and test with real data. At this stage, speed feels more important than architectural boundaries.
This is where the first mistake usually happens.
In multiple reported healthcare AI incidents over the past few years, the core issue was not malicious intent but uncontrolled data flow. Teams experimented first and mapped boundaries later. By the time someone asked, “Does this require PHI?”, prompts already contained protected health information, logs persisted sensitive inputs, and model calls had crossed external vendor boundaries.
Early AI adoption blurs categories. Clinical text feels like “just text.” Operational metadata appears harmless. A quick API call feels temporary. But in regulated healthcare environments, temporary decisions harden into architecture.
PHI vs non-PHI separation is not a refinement step. It is the first boundary that determines how safely an AI system can scale. In our previous pillar on HIPAA-compliant AI architecture, we examined how secure systems enforce this separation at the infrastructure level. Here, the focus is earlier: defining what AI can and should not touch before those boundaries become expensive to retrofit.
Because once PHI enters an AI system without control, reversing exposure is significantly harder than preventing it.
What Counts as PHI in AI Systems Beyond the Obvious
When teams think about PHI, they picture direct identifiers: names, addresses, Social Security numbers, and medical record numbers. In AI systems, the boundary is broader.
Free-Text Clinical Notes
Free-text clinical notes are the most underestimated risk surface. Even when obvious identifiers are removed, narrative text often contains rare diagnoses, timelines, or contextual details that enable re-identification. This is one reason regulators consistently emphasize that de-identification is not simply “removing names.”
To be truly compliant, datasets often need to meet mathematical standards like k-anonymity, where an individual’s record is indistinguishable from at least k-1 others, preventing re-identification through unique combinations of indirect attributes.
Metadata
Metadata is another blind spot. Timestamps, facility identifiers, internal routing IDs, or conversation logs may not look sensitive individually. Combined, they can reconstruct patient journeys.
Embeddings
Embeddings complicate the picture further. Vector databases store mathematical representations of text derived from PHI. While not human-readable, they are still derived from protected information. If embeddings are retrievable, searchable, and linked to patient context, they remain part of the compliance surface.
Model Outputs
Model outputs matter as well. Several industry audits have shown that generative models can reintroduce sensitive details even when inputs are partially sanitized. Summaries, explanations, and structured outputs may inadvertently reattach context if storage and routing are not tightly controlled.
The "Memorization Trap" and Synthetic PHI
Beyond direct exposure, there is the risk of model memorization. LLMs trained or fine-tuned on medical corpora can sometimes "leak" snippets of real-world data they encountered during training. A model might output a specific provider’s name or a rare patient case detail not because it’s in your current prompt, but because it became part of the model’s statistical weights.
Even "hallucinated" PHI, data the model invents that merely looks like a real Social Security number or Patient ID, creates significant operational risk. These synthetic identifiers can trigger security alerts and automated DLP (Data Loss Prevention) blocks, forcing your team into costly and time-consuming forensic audits to prove that a data breach didn't actually occur. In a regulated environment, if it looks like PHI, the system must treat it as a potential exposure until proven otherwise.
Core Principle
PHI is defined by origin and reconstructability, not by format. If data originates from protected health information and can be tied back to an identifiable individual, it belongs inside controlled boundaries.
What AI Can Safely Touch Without Expanding Compliance Risk
AI adoption does not require immediate exposure to raw patient data. In fact, many high-value use cases operate entirely outside PHI boundaries.
Operational Intelligence
Operational analytics, capacity planning, staffing optimization, and supply chain forecasting typically rely on aggregated or de-identified datasets. These systems can deliver measurable impact without touching identifiable records.
Internal Workflow Automation
Internal workflow automation is another safe starting point. Ticket routing, documentation templates, internal knowledge assistants, and policy summarization tools rarely require direct patient identifiers. Constraining inputs at the API level dramatically reduces risk.
Patient Education Tools
Patient-facing education tools also fall into this category when designed correctly. FAQ assistants, structured symptom explainers, and guidance tools can operate on curated knowledge bases without retrieving live medical histories.
Even de-identified summarization can be architected safely when tokenization occurs upstream, and reattachment to patient records happens inside controlled environments.
The guiding rule is data minimization. If a model does not need identifiable data to perform its function, it should never see it.
What AI Should Not Touch Without Architectural Controls
AI should not interact with raw clinical data unless clear technical safeguards are already in place. Sending unfiltered patient records, full clinical notes, or live EHR extracts to external model APIs is not an experimentation shortcut. It is a regulated data transfer.
Logging Identifiable Prompts to Third-Party Tools
Prompts that contain identifiable information should never be logged to third-party monitoring tools without redaction. Many observability systems store request and response payloads by default. If those payloads contain PHI, compliance exposure expands beyond the primary application layer.
The Human-in-the-Loop Blind Spot
Many teams overlook the compliance surface of human review stages. If an engineer, data scientist, or clinician accesses unredacted logs or raw datasets to "debug" a model or validate its outputs, that interaction is a regulated data access event. Without strict access controls, audit trails, and data minimization at the review interface, the "human-in-the-loop" becomes the weakest link in the compliance chain. Every human touchpoint must be treated as a system boundary, not a workaround for technical redaction.
Fine-Tuning Without Environment Isolation
Fine-tuning models on clinical data without strict environment isolation is another high-risk pattern. Training workflows often persist datasets, checkpoints, and artifacts. Without explicit controls, PHI can spread across development and staging environments.
Mixing Production PHI with Development Data
Mixing production PHI with development datasets is equally problematic. Test environments frequently reuse real patient data for convenience. Once AI components are evaluated or debugged on live records outside approved boundaries, proving containment becomes difficult.
Inference Beyond Authorization Scope
Finally, AI systems should not infer beyond their authorization scope. Even if direct identifiers are removed, allowing models broad contextual access increases the likelihood of reconstructing sensitive information in outputs.
The common pattern across these scenarios is uncontrolled exposure. When AI systems touch PHI without enforced boundaries, risk compounds silently as new features are added.
A Practical Decision Boundary for Early AI Teams
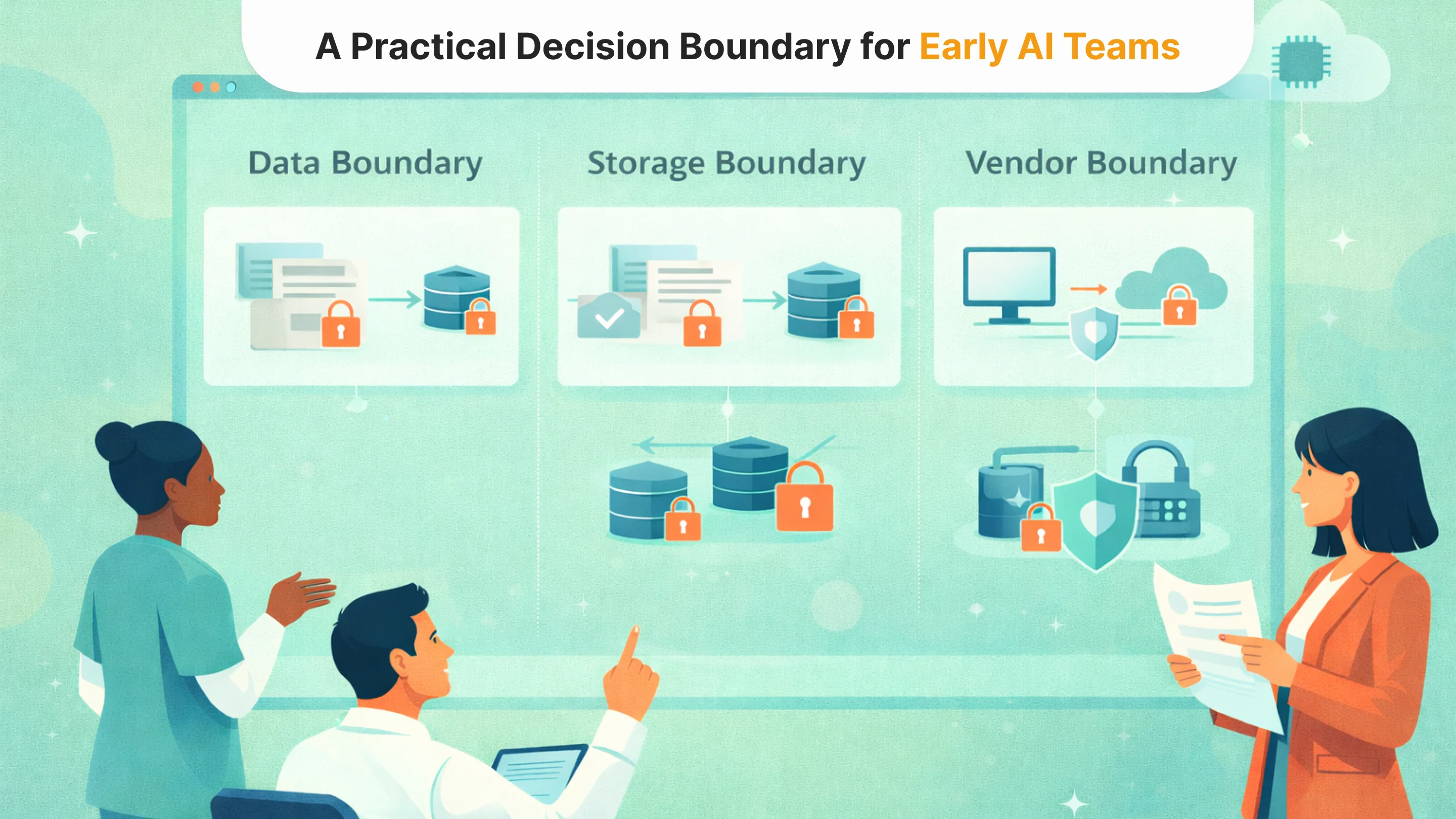
Before integrating AI into any healthcare workflow, the most important step is not model evaluation. It defines the data boundary.
Every proposed use case should begin with a simple architectural question: Does this functionality truly require raw PHI, or can it operate on de-identified or structured substitutes? In many early experiments, teams default to using live clinical data because it is accessible and realistic. But realism is not the same as necessity.
If raw identifiers are not required for the task, they should never reach the model. If narrative context is sufficient, identifiers can be tokenized upstream. If structured fields can replace free text, exposure can be reduced significantly. These are engineering decisions, not legal ones.
The second boundary concerns storage and observability. Where will prompts and outputs be persisted? Who has access to logs? Are embeddings derived from sensitive content retrievable outside controlled environments? AI systems generate secondary data artifacts, and those artifacts often outlive the original experiment.
The third boundary involves vendors. Every external model call, monitoring tool, or analytics service extends the compliance surface. Even when vendors are contractually covered, architectural minimization still matters. The fewer systems that touch PHI, the smaller the blast radius of any failure.
Early AI adoption becomes far safer when teams treat PHI exposure as something that must be justified, not assumed. If a use case cannot clearly explain why it needs identifiable data, that is usually the first signal that architectural discipline is required.
These decisions may feel incremental at the start. But they determine whether AI remains an experiment or becomes a scalable, compliant capability.
Defining the Boundary Before You Build
PHI vs non-PHI separation is not a legal formality. It is the first architectural decision in healthcare AI adoption. Once protected data flows into a system without clear constraints, reversing that exposure becomes complex and expensive.
Teams that define boundaries early move faster in the long run. They reduce vendor risk, simplify observability, and avoid retrofitting compliance controls after pilots have already expanded.
In our pillar on HIPAA-compliant AI architecture, we outlined how these boundaries are enforced at the system level. This article focused on the earlier step: deciding what AI should touch before architecture becomes difficult to unwind.
If you are evaluating new AI use cases in healthcare, start with the boundary. The model can wait.

Tell us about your project
Fill out the form or contact us

Tell us about your project
Thank you
Your submission is received and we will contact you soon
Follow us